近年、AI技術の進化に伴い、ウェブサイトを巡回するAIボットの数が急増しています。
これらのAIボットは有益な情報収集を行う場合もありますが、一方で以下のようなリスクをもたらすこともあります。
- 短時間に膨大なアクセスを行い、サイトのパフォーマンスを大幅に低下させる。
- 不必要なページまでクロールし、機密情報が漏洩する可能性がある。
また、会員専用サイト等、検索エンジンにインデックスさせる必要がない・インデックスされたくないページやサイトでは、検索エンジンのクローラーを拒否したり「noindex」設定を行うことが不可欠です。
本記事では、これらの脅威からウェブサイトを守るために、AIボットや検索エンジンのクロールを拒否する効果的な7つの方法をご紹介します。
これらの対策を講じることで、大切なサイトを守り、安全で快適な環境を維持することができるでしょう。
なお、当ページに書いてある7つの方法に関して、4つ目の「WordPressプラグインで拒否する」以外の6つはGoogleアナリティクス・Googleサーチコンソール・Bing Webmaster Tools等のクロールには影響ありません。
「WordPressプラグインで拒否する」についても、(私はインストール・有効化してないので詳細は不明ですが)他のプラグインと同じ機能の設定をしなければたぶん問題ありません。
- robots.txtでAIクローラーを拒否する
- WordPressの設定でnoindexにする
- WordPressテーマのheader.phpで検索エンジンのクローラーを拒否する
- WordPressのプラグインでAIボットと検索エンジンを拒否する
- .htaccessにX-Robots-Tagを追加する
- Bytespider対策を追加する
- ■注意その1その2■ここまでの注意点まとめ
- 【推奨】CloudflareでAIボットを拒否する(必要に応じて検索エンジンも拒否)
- 【番外編】Cloudflareで提供されている、超簡単なAIボット対策3つ
robots.txtでAIクローラーを拒否する
robots.txtファイルを使って、特定の検索エンジンやボットがウェブサイトをクロールできないようにする設定方法です。
サイトのルートディレクトリにrobots.txtファイルを配置し、クローラーのアクセスを制御します。
特定のボットや特定のディレクトリへのアクセスを拒否できます。
下記の内容で robots.txt を作成し、FTPソフトでドメイン直下にアップロードします。
https://ほにゃらら.com/robots.txt
になります。
最後の2行の「ほにゃらら.com」はご自身の環境にあわせて下さい。
##■■■AIボットをブロック■■■
User-agent: AI2Bot
User-agent: Amazon-Kendra
User-agent: AmazonAdBot
User-agent: Applebot-Extended
User-agent: Bytespider #robots.txtを無視する
User-agent: CCBot
User-agent: ChatGPT-User
User-agent: ClaudeBot
User-agent: cohere-ai
User-agent: DeepSeek #念のため追加
User-agent: DeepSeekBot
User-agent: Diffbot
User-agent: Discordbot
User-agent: GPTBot
User-agent: Google-Extended
User-agent: GoogleOther
User-agent: GoogleOther-Image
User-agent: GoogleOther-Video
User-agent: GrokBot
User-agent: ICC-Crawler
User-agent: ImagesiftBot
User-agent: Linguee
User-agent: Mail.RU_Bot
User-agent: Mappy
User-agent: MegaIndex
User-agent: meta-externalagent
User-agent: meta-externalfetcher
User-agent: MistralBot
User-agent: OAI-SearchBot
User-agent: PerplexityBot
User-agent: SMTBot
User-agent: The Knowledge AI
User-agent: xAI-Bot #念のため追加
User-agent: YouBot
Disallow: /
##■■■検索エンジンのボットをブロック■■■
##■これを有効にすると各ページの<head>内のインデックス禁止コードを読み取らなくなるので、これは無効にしておいて<head>内を優先させる
#■User-agent: 360Spider
#■User-agent: AdsBot-Google
#■User-agent: AhrefsBot
#■User-agent: Amazonbot
#■User-agent: Applebot #SiriとSpotlight
#■User-agent: archive.org_bot
#■User-agent: Baiduspider
#■User-agent: Baiduspider-image
#■User-agent: Baiduspider-video
#■User-agent: Bingbot
#■User-agent: BingPreview #Bingの画像検索
#■User-agent: BLEXBot
#■User-agent: coccocbot
#■User-agent: DataForSeoBot
#■User-agent: DuckAssistBot
#■User-agent: DuckDuckBot
#■User-agent: Exabot
#■#▲User-agent: Facebookexternalhit #Facebook・インスタ・Messengerの共有
#■User-agent: FeedlyBot
#■#▲User-agent: Google-InspectionTool #Googleのリッチリザルト・テスト や URL 検査ツール
#■User-agent: Google-PageRenderer
#■User-agent: Googlebot
#■User-agent: Googlebot-Image
#■User-agent: Googlebot-News
#■User-agent: Googlebot-Video
#■#▲User-agent: Linebot #ラインの共有
#■User-agent: MJ12bot #Majestic SEO
#■User-agent: Mediapartners-Google #Google AdSense
#■User-agent: Meta-ExternalAgent #robots.txtを無視するかも
#■#▲User-agent: Meta-ExternalFetcher #Facebook・インスタ・Messengerの共有・robots.txtを無視するかも
#■User-agent: linkdexbot
#■User-agent: Nimbostratus-Bot
#■User-agent: PetalBot
#■User-agent: Qwantify
#■User-agent: rogerbot
#■User-agent: searchbot
#■User-agent: SEOkicks
#■User-agent: SemrushBot
#■User-agent: Sogou
#■User-agent: Sogou web spider
#■User-agent: Storebot-Google
#■#▲User-agent: Twitterbot #Twitterの共有
#■User-agent: Uptimebot
#■User-agent: Yahoo! Slurp
#■User-agent: YandexBot
#■User-agent: YisouSpider
#■Disallow: /
##■■■すべてのボットをブロック■■■
##■これを有効にすると各ページの<head>内のインデックス禁止コードを読み取らなくなるので、これは無効にしておいて<head>内を優先させる
#■#▲User-agent: *
#■#▲Disallow: /
##■■■広告・マーケティング関連のボットをブロック■■■
User-agent: AdsTxtCrawler
User-agent: Centro Ads.txt Crawler
User-agent: CipaCrawler
User-agent: GetIntent Crawler
User-agent: IABTechLab Ads.txt Crawler
User-agent: PubMatic Crawler Bot
User-agent: SurdotlyBot
Disallow: /
##■■■その他のクローラーをブロック■■■
User-agent: heritrix
User-agent: Slack-ImgProxy
User-agent: Steeler
User-agent: TweetmemeBot
Disallow: /
##■■■念の為、WooCommerce用■■■
Disallow: /cart/
Disallow: /checkout/
Disallow: /my-account/
Disallow: /wc-api/
Disallow: /?add-to-cart=
Disallow: /?orderby=
Disallow: /?s=
##■■■WordPressの管理画面用■■■
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
##■■■検索エンジン等がCloudflareの/cdn-cgi/ に誤アクセスする対策■■■
Disallow: /cdn-cgi/
Sitemap: https://ほにゃらら.com/sitemap.xml
Sitemap: https://ほにゃらら.com/sitemap.html
ジャンル分けが若干間違ってるかもしれないです。
m(_ _)m
■注意その1■
上記の内容の robots.txt をアップロードする前に現在の robots.txt の内容を確認して、WordPress本体あるいは各種プラグインが自動生成する robots.txt の内容を削除しないようにする必要があります。
まず最初に
https://ほにゃらら.com/robots.txt
にアクセスして既存の robots.txt の内容を確認してから上記 robots.txt の内容を追記して下さい。
■注意その2■
robots.txt をサブディレクトリに設置しても読み込まれません。
サブディレクトリをクロール拒否したい場合は、ルートドメイン(ドメイントップ)の robots.txt に
User-agent: *
Disallow: /●サブディレクトリ名●/と記述します。
ボットの種類に関してはググれば解説サイトがたくさんヒットしますが、

をご覧下さい。
少し補足説明します。
上記 robots.txt の内容は
- 各AIボットを拒否
- 各検索エンジンのボットは許可
となっています。
各検索エンジンのボットのクロールを拒否していない理由は、後述の「WordPressテーマのheader.phpで拒否する」を優先させるためです。
「WordPressテーマのheader.phpで拒否する」の設定をしつつ robots.txt でも検索エンジンのボットをブロックすると、検索エンジンは robots.txt の指示に従い各ページをクロールしません。
この状態でもし他サイトからリンクされている場合、リンク先をクロールするのでリンク先のページがインデックスされてしまう可能性があります。
これを回避するために、あえて robots.txt では各検索エンジンのクロールは禁止せず、後述の「WordPressテーマのheader.phpで拒否する」にて各検索エンジンのクロールをブロックします。
もしその必要がない場合は、上記 robots.txt 内の
##■■■検索エンジンのボットをブロック■■■
##■これを有効にすると各ページの<head>内のインデックス禁止コードを読み取らなくなるので、これは無効にしておいて<head>内を優先させる
#■User-agent: 360Spider
#■User-agent: AdsBot-Google
#■User-agent: AhrefsBot
#■User-agent: Amazonbot
#■User-agent: Applebot #SiriとSpotlight
#■User-agent: archive.org_bot
#■User-agent: Baiduspider
#■User-agent: Baiduspider-image
#■User-agent: Baiduspider-video
#■User-agent: Bingbot
#■User-agent: BingPreview #Bingの画像検索
#■User-agent: BLEXBot
#■User-agent: coccocbot
#■User-agent: DataForSeoBot
#■User-agent: DuckAssistBot
#■User-agent: DuckDuckBot
#■User-agent: Exabot
#■#▲User-agent: Facebookexternalhit #Facebook・インスタ・Messengerの共有
#■User-agent: FeedlyBot
#■#▲User-agent: Google-InspectionTool #Googleのリッチリザルト・テスト や URL 検査ツール
#■User-agent: Google-PageRenderer
#■User-agent: Googlebot
#■User-agent: Googlebot-Image
#■User-agent: Googlebot-News
#■User-agent: Googlebot-Video
#■#▲User-agent: Linebot #ラインの共有
#■User-agent: MJ12bot #Majestic SEO
#■User-agent: Mediapartners-Google #Google AdSense
#■User-agent: Meta-ExternalAgent #robots.txtを無視するかも
#■#▲User-agent: Meta-ExternalFetcher #Facebook・インスタ・Messengerの共有・robots.txtを無視するかも
#■User-agent: linkdexbot
#■User-agent: Nimbostratus-Bot
#■User-agent: PetalBot
#■User-agent: Qwantify
#■User-agent: rogerbot
#■User-agent: searchbot
#■User-agent: SEOkicks
#■User-agent: SemrushBot
#■User-agent: Sogou
#■User-agent: Sogou web spider
#■User-agent: Storebot-Google
#■#▲User-agent: Twitterbot #Twitterの共有
#■User-agent: Uptimebot
#■User-agent: Yahoo! Slurp
#■User-agent: YandexBot
#■User-agent: YisouSpider
#■Disallow: /
##■■■すべてのボットをブロック■■■
##■これを有効にすると各ページの<head>内のインデックス禁止コードを読み取らなくなるので、これは無効にしておいて<head>内を優先させる
#■#▲User-agent: *
#■#▲Disallow: /の箇所に関して、
##■■■検索エンジンのボットをブロック■■■
と
##■■■すべてのボットをブロック■■■
と
##■これを有効にすると各ページの<head>内のインデックス禁止コードを読み取らなくなるので、これは無効にしておいて<head>内を優先させる
以外の先頭の「#■」を削除して下さい。
※「#■」を「」で一括置換しても大丈夫なようにしてあります。
この場合でも「#■#▲」の箇所はそのままにしておくことをオススメします。
「#■#▲」の箇所を有効にすると、インスタ・Twitter等の共有リンクの見た目やGoogleのリッチリザルト・テストの挙動等がおかしくなります。
WordPressの設定でnoindexにする
WordPressの設定から「noindex」を指定することで、検索エンジンがページをインデックスしないようにする方法です。
WordPressであれば、WordPressの管理画面から簡単にサイト全体のnoindex設定ができます。
テーマによっては、あるいはSEOプラグインを使用すれば、個別ページごとのnoindex設定も可能です。
WordPressにログインして、設定 → 表示設定の「検索エンジンでの表示」にて、
検索エンジンがサイトをインデックスしないようにする:チェックON
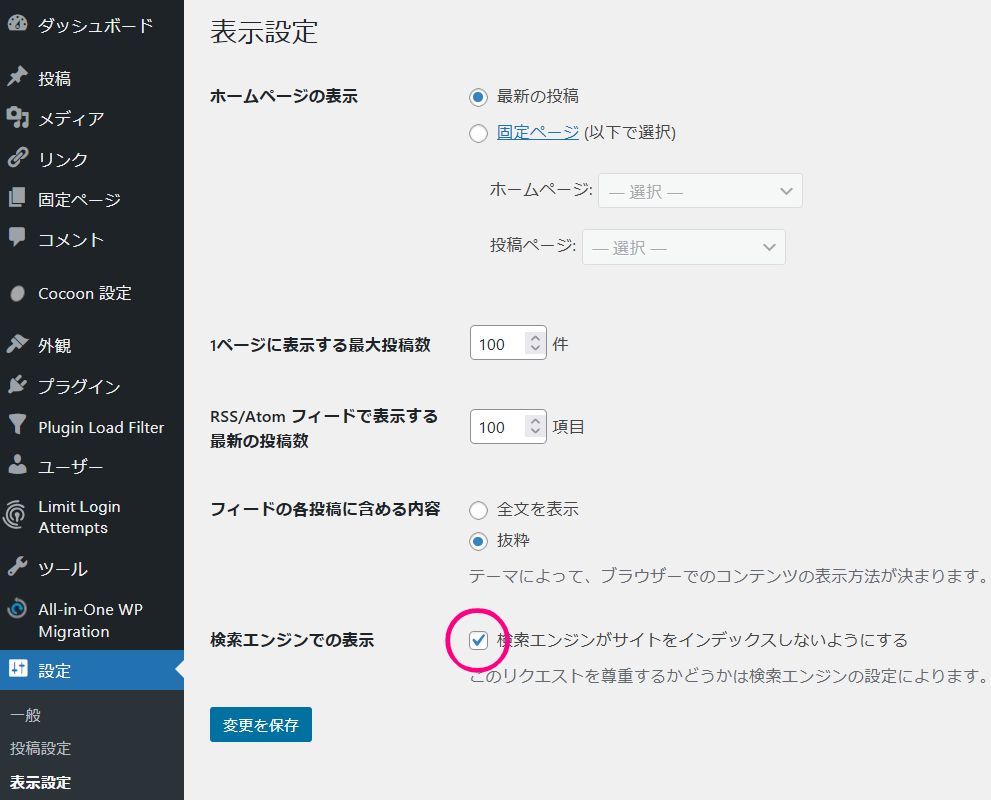
で「変更を保存」をクリックするとサイト全体をインデックスしない設定になります。
※全ページの<head>に <meta name="robots" content="noindex"> が自動挿入されます。
この <meta name="robots" content="noindex"> はGoogle・Bingはちゃんと守りますが、AIボットの中には無視するボットもあります。
後述の「WordPressテーマのheader.phpで拒否する」のコードのほうがベターですが、検索エンジンにインデックスさせない・AIボットにクロールして欲しくないWordPressサイトの場合はこの設定もしておいたほうが無難です。
WordPressテーマのheader.phpで検索エンジンのクローラーを拒否する
テーマのheader.phpファイルを編集し、noindexだけではなく可能な限り全て拒否するコードを直接挿入します。
別にWordPressでなくても <head> 内に下記コードを追加すればOKです。
WordPressのテーマのheader.phpの
<head>
<meta charset="utf-8">
のすぐ下あたりに以下のコードを追加します。
<!--■BOTとAIのクロールを拒否する■-->
<meta name="robots" content="noindex, nofollow, noarchive, noimageindex, noai">
<meta name="bingbot" content="noindex, nofollow, noarchive">
<meta name="pinterest" content="noindex, nopin">- 各AIボットを拒否
- 各検索エンジンのボットも拒否
このコードはGoogle・Bingはちゃんと守りますが、AIボットの中には無視するボットもあります。 Bytespiderとか
■検索エンジンを拒否
noindex:インデックスの拒否
nofollow:ページ内のリンクを辿らないようにクローラーへ要求
noarchive:検索エンジンデータベースへの保存の拒否
noimageindex:画像をインデックスさせない
■AIボットのクロールを拒否(単なる要望)
noai:AI学習の拒否を要望。
このタグは提唱されているだけなので、現時点で noindex, nofollow, noarchive, noimageindex, noai の全てを無視するAIボットも多いはずです。
将来的にAI業界全体にこのタグが浸透しても、このタグだけでAIボットのクロール拒否は無理な気がします
無視するAIボットは必ず存在するので。Byte(ryとか
現時点で1番確実にAIボットを拒否する方法は、CloudflareのWAFでAIボットを拒否する です。
WordPressのプラグインでAIボットと検索エンジンを拒否する
WordPressの場合はAIボットや検索エンジンのクロールを拒否できるプラグインがいくつかあります。
現時点では私はプラグインでのクロール拒否設定はしてないです。
つまり、下記プラグインは1つも使っていません。
■Shield: Blocks Bots, Protects Users, and Prevents Security Breaches

■特徴
包括的なセキュリティプラグインで、ボットのブロックだけでなくユーザー保護やセキュリティ侵害の防止にも役立ちます。
ボット攻撃の防御に特化・silentCAPTCHAによるボット検出・詳細なアクティビティログ・ログイン試行回数の制限・ユーザー登録スパムのブロック・二要素認証(2FA)・ファイルスキャナによる改ざん検出・CrowdSecとの連携によるIPブロックリスト活用など、強力なファイアウォール機能・ログインセキュリティ・スパム対策などが含まれます。
AIボットのブロックにも対応しています。
■有料・無料
無料版と有料版(ShieldPRO)があります。
有料版では、より高度なセキュリティ機能やサポートが利用可能です。
■BBQ Firewall – Fast & Powerful Firewall Security

■特徴
高速かつ強力なファイアウォールプラグインで、悪意のあるクエリをブロックします。
軽量でリソース消費が少ないのでパフォーマンスへの影響が少ないため、高速なウェブサイトを維持できます。
シンプルで設定が簡単です。
悪質なボットのアクセスを遮断します。
■有料・無料
無料版のみ
■Blackhole for Bad Bots

■特徴
「ブラックホールと呼ばれる」リンクを設置し悪質なボットをトラップ、それにアクセスしたボットをブロックします
ボットが誤ってブラックホールにアクセスした場合、自動的にブロックリストに追加されます。
AIボットのアクセスも遮断します。
■有料・無料
無料版のみ
■AI Deny

■特徴
AIボットのアクセスを拒否することに特化した、比較的新しいプラグイン。
AIを利用してボットを識別し、AIボットのアクセスを拒否します。
AIボットのアクセスを拒否するためのメタタグを自動的に追加し、robots.txtの設定も可能で、設定が簡単です。
AIによる精度の高いブロックが特徴です。
■有料・無料
無料版のみ
■Stop and Block bots plugin Anti bots

■特徴
多層防御により、悪意のあるボットやスパムをブロックします。
IPアドレス・ユーザーエージェント・リファラなどの情報に基づいてボットを検出します。
AIボットのアクセスも遮断します。
■有料・無料
無料版のみ
もし私が上記プラグインのどれかを使うなら、AI Deny かな、と思います。
.htaccessにX-Robots-Tagを追加する
.htaccessファイルにX-Robots-Tagヘッダーを追加し、サーバーレベルでクロールを制御します。
特定のファイルやページだけのインデックスを防ぐことも可能です。
.htaccessに
<IfModule mod_headers.c>
Header always set X-Robots-Tag "noindex,nofollow,noarchive,noimageindex,noai"
</IfModule>と記述します。
.htaccessに
<IfModule mod_headers.c>
Header always set X-Robots-Tag "noindex,nofollow,noarchive,noimageindex,noai"
</IfModule>
と記述する方法と、
ソースの <head> 内に
<!--■BOTとAIのクロールを拒否する■-->
<meta name="robots" content="noindex, nofollow, noarchive, noimageindex, noai">
と記述する方法との違いは、
■.htaccess のX-Robots-Tag
.htaccessによる設定は、サーバーレベルでの指示となります。
これにより、特定のディレクトリやファイルに対する指示を一括して設定できます。
サーバーからの応答ヘッダーにX-Robots-Tagを追加するため、HTMLファイルだけでなく画像やPDFなどの他のファイルタイプにも適用できます。
サーバー側での設定となるため、HTMLファイルが生成される前に指示を出すことができます。
■HTMLの <meta name="robots">
HTMLの <meta name="robots"> タグは、ページレベルでの指示となります。
個々のHTMLファイル内に記述する必要があり、そのページにのみ適用されます。
※WordPress設定での「検索エンジンがサイトをインデックスしないようにする」は全ページ一括設定する仕組みです。
HTMLファイルを解析できるクローラーにのみ有効です。
画像やPDFなどの他のファイルタイプには適用されません。
HTMLファイルが生成された後に、指示を出すことになります。
■設定の優先順位
一般的に、X-Robots-Tagの方が <meta name="robots"> タグよりも優先されます。つまり、両方の設定が矛盾する場合、X-Robots-Tagの設定が優先されます。
特にボットがページをクロールする際には、HTTPヘッダーのX-Robots-Tagを優先的に確認することがあります。
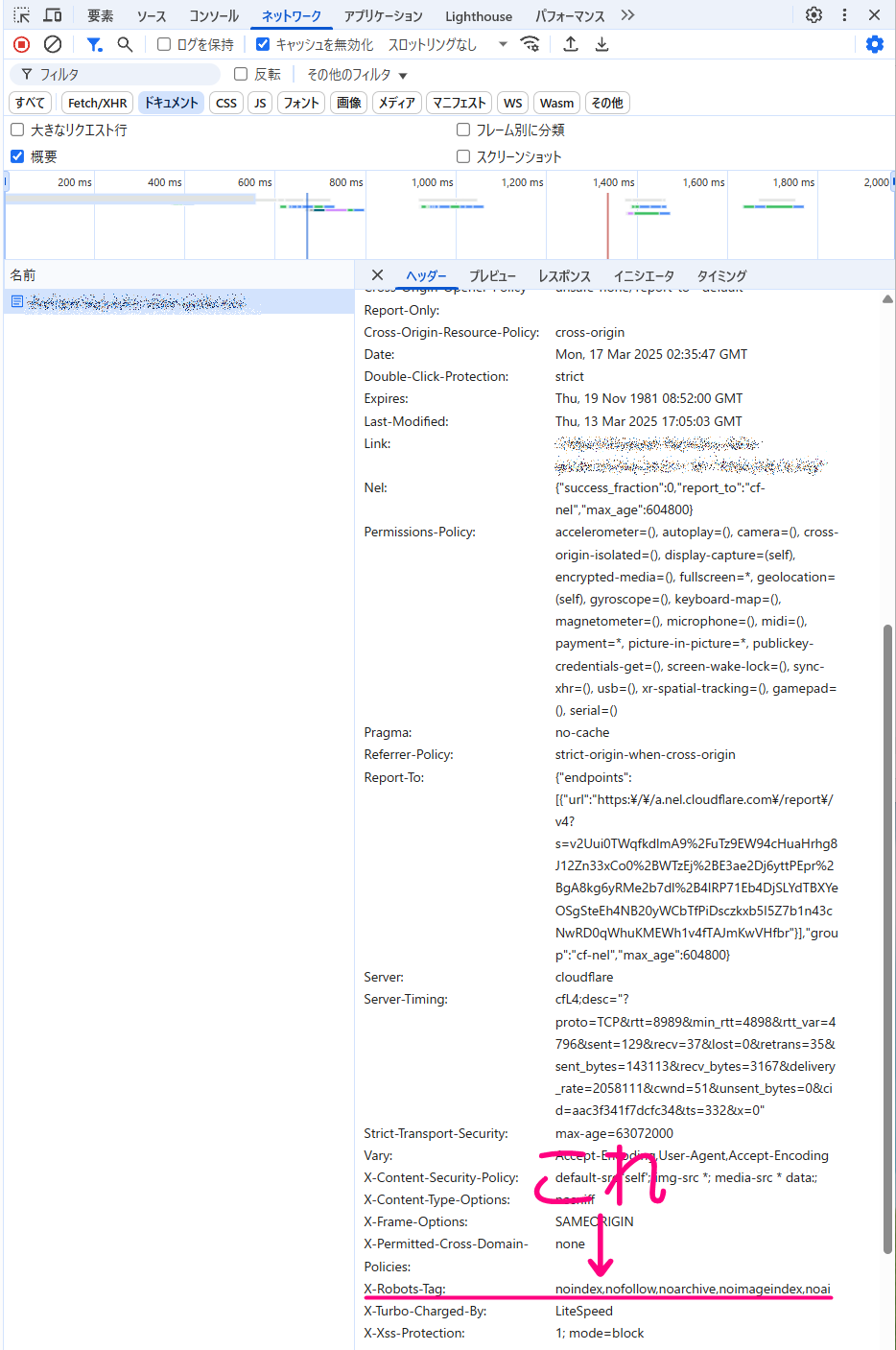
ちゃんとX-Robots-Tagが設定できているかの確認は、
F12キーでデベロッパーツール・ウェブ開発ツール(開発者モード)を開く
↓
「ネットワーク」タブにて、「ドキュメント」あるいは「HTML」をクリックしたらページを読み込む
↓
読み込んだhtmlをクリック
そうするとヘッダーの内容が表示されるので、その中に
x-robots-tag:noindex,nofollow,noarchive,noimageindex,noai
という項目があれば設定できています。
Bytespider対策を追加する
Bytespider(ByteDance社のクローラーでTikTok関連のAIボット)はrobots.txtやheader.phpのnoindexの記述を無視すると言われています。
その上、Bytespiderはユーザーエージェントを「Googlebot-Image」と偽装してアクセスしてくることがあるみたいで悪質です。
そこで、ここまでの作業で設定した
- .htaccess
- robots.txt
- header.php
の各記述に加えて、特に悪質なBytespiderからのクロールを拒否します。
.htaccess に以下の記述を追加しておきます。
# ■Bytespider対策(補助的)
BrowserMatchNoCase "Bytespider" spam_crawler
<RequireAll>
Require all granted
Require not env spam_crawler
</RequireAll>ただし、Bytespiderはrobots.txtやheader.phpのnoindexの記述を無視する可能性が非常に高いので、あくまで補助的な対策です。
後述のCloudflareのWAFで拒否するほうが確実です。
前述のプラグインでも、使い方次第では確実性があるかもしれません。
ただしプラグインによってはクローラー拒否以外にファイアーウォール的・総合的なセキュリティ機能のプラグインもあるので注意が必要です。
その理由 + AIを使って判断している点を考慮して
もし私が上記プラグインのどれかを使うなら、AI Deny かな、と思います。
とチョイスした次第です。
なお、現時点ではBytespiderのBOTのユーザーエージェントは「Bytespider」のみでほぼ間違いないみたいです。
今後変更される可能性もあります。
■注意その1その2■ここまでの注意点まとめ
ここまでの対策での注意点として2つ、
■注意その1
robots.txt をアップロードする前に現在の robots.txt の内容を確認して、WordPress本体あるいは各種プラグインが自動生成する robots.txt の内容を削除しないようにする必要があります。
まず最初に
https://ほにゃらら.com/robots.txt
にアクセスして既存の robots.txt の内容を確認してから上記 robots.txt の内容を追記して下さい。
■注意その2
サブディレクトリをクロール拒否したい場合は、ルートドメイン(ドメイントップ)の robots.txt に
User-agent: *
Disallow: /●サブディレクトリ名●/と記述します。
※サブディレクトリ用の.htaccessはサブディレクトリに設置します。
です。
各ファイルをFTPソフトでアップロードしたら、その都度「ちゃんと設定できているか」、デベロッパーツール・ウェブ開発ツール(開発者モード)・各種Webサービス等で確認してみて下さい。
【推奨】CloudflareでAIボットを拒否する(必要に応じて検索エンジンも拒否)
私はCloudflareのエッジキャッシュは使ってないのですが、セキュリティ対策としてCloudflare自体は経由させています。
というか、元に戻すのが面倒なのでそのままなだけなんですが。。。
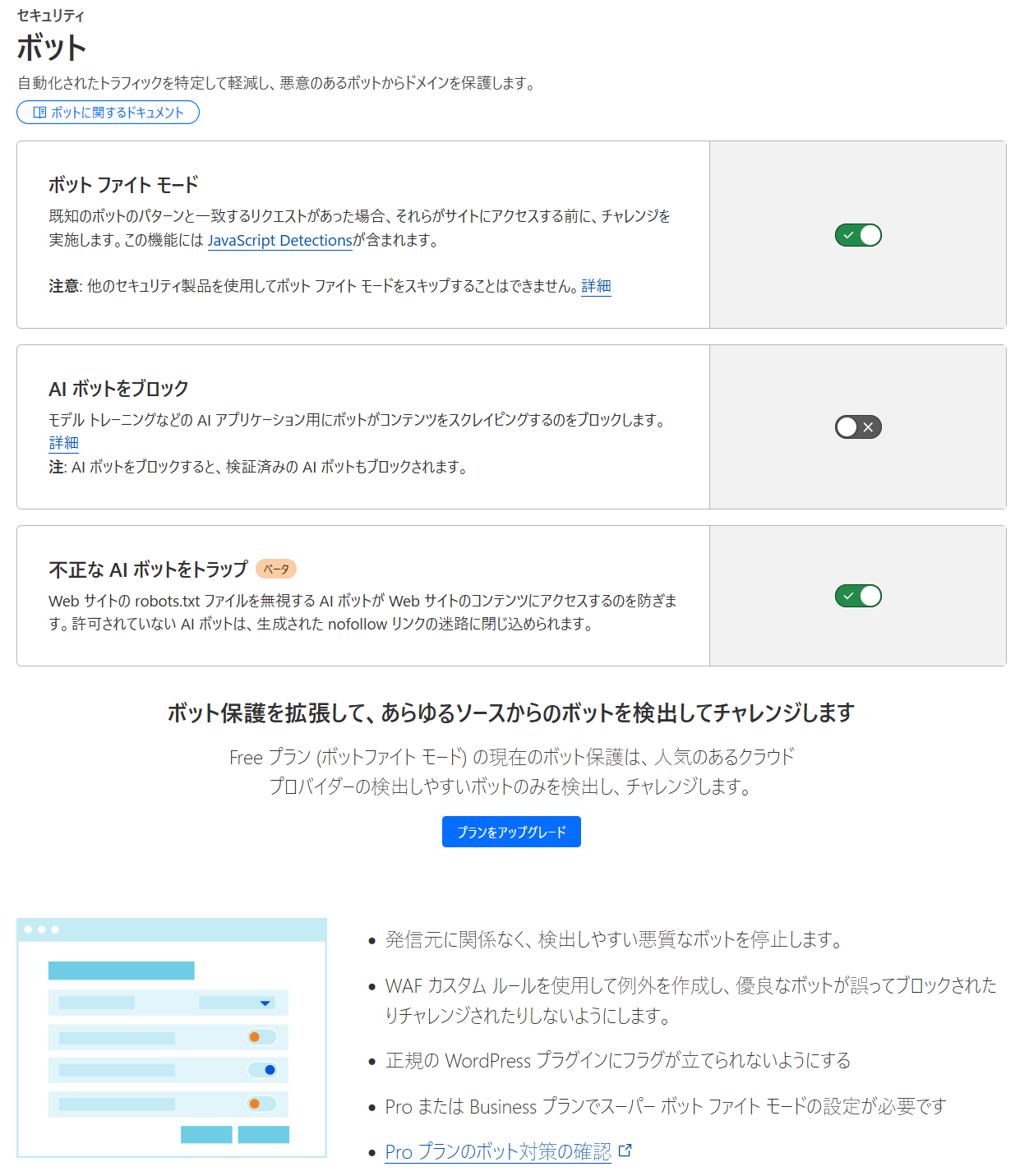
Cloudflareには「AIボットをブロック」という大変便利な機能があり、ワンクリックでかなりの種類のAIボットをブロックできますが、今回はCloudflareのWAF(Web Application Firewall)を使用し、AIボットからのアクセスを遮断します。
Cloudflareの「AIボットをブロック」あるいはWAFの機能は、今まで書いた対策と比べて(検索エンジンのボットも含めて)AIボットのクロールを確実に拒否できる可能性が非常に高いです。
その上、WAFの場合は高度な設定が可能です。
Cloudflareの無料プランの場合、適切に設定しないとWordPress管理画面にログインした状態のページがキャッシュされることがあります。
ご自身でちゃんと設定できなさそうな場合あるいは心配な場合は

をお申し込みいただければ、Cloudflareの基本的な設定およびWordPressログイン状態をキャッシュしない設定までお引き受けいたします。
CloudflareでAIボットを拒否する方法をオススメする理由
robots.txtでAIボットのクローラーを拒否してもユーザーエージェントを偽装されれば簡単に突破されます。
また、robots.txtは紳士協定(お願い的なやつ)なので、全てのAIボットが遵守するわけではありません。
nofollow・noindexに関して、Googleでさえたまに無視してクロールします。
Cloudflareの「AIボットをブロック」あるいはWAFの機能における
- AIボット
- 検索エンジンのボット
であるという判断はCloudflareの膨大なネットワーク(1秒間に平均5700万件以上のリクエストを処理できる)で処理されるデータを活用して、AIボットの行動パターンを学習し、高精度で検出します。
例えば、Bytespiderのような悪意のあるAIボットがユーザーエージェントを偽装したとしてもその他の特徴から「ボットらしさ」をスコア化し、スコア30点以下のアクセスを自動的にブロックします。
スコア化したボットは、後述の検証済みボット・既知のボットの各リストに定期的に更新・追加されます。
robots.txtは自分で更新しない限り古い内容のまま(※1)ですが、Cloudflareの検証済みボット・既知のボットの各リストは定期的に更新されるため常に最新のボットリストになり、これはセキュリティ的に優位です。
※1 とは言っても当ページの「robots.txtで拒否する」の箇所の内容は、当面はかなりの割合のAIボットをカバーできるはずです。
ワンクリックで設定できる「AIボットをブロック」だと後述のサイト8がインデックスされなくなるので、後述の9サイトはWAFで設定します。
以下、CloudflareでAIボットを拒否する設定手順を9サイトを例に説明します。
【初心者向け】1サイト/1ドメインを丸ごとAIボット拒否する
1サイトしかない場合や1ドメイン丸ごとAIボット拒否でOKな場合は、Cloudflareの設定 → セキュリティ → ボットにある「AIボットをブロック」という一括設定をチェックONにするだけでOKです。
ただし、後述のCloudflareのアカウントAのWAF設定のほうがブロックするボットの数が多いです、たぶんですけど。
この「AIボットをブロック」でブロックされるAIボットの種類は、
- 全ての検証済みボット
および
- 「検証済みボット」カテゴリーに分類される多数の未検証ボット
をブロックします。
- 検索エンジン カテゴリに分類される検証済みボットはブロックされません。
とのことです。

【中級者向け】複数サイト/複数ドメインでAIボット拒否設定を行う方法
複数サイト・複数ドメインの場合や少し複雑な設定が必要な場合は以下をお読みいただき、ご自身の環境にあわせて条件・値等を修正してみてください。
Cloudflareの無料アカウントでOKですが、今までの設定と比べて少し難易度が高(ry・・・くもないか。
初見だと難しそうに思えるかもしれませんが、Cloudflareの設定画面を何度かいじっていれば簡単です。
以下、私の手持ちの9サイト・Cloudflareアカウント2つで具体的に説明しますが、
- WordPressで1サイトのみの場合は、CloudflareのアカウントAのWAF設定そのままでOKです。
- WordPressではない1サイトの場合は、値:/wp-admin/ の箇所を管理画面のURLの一部に修正すればOKなはずです。
1サイトのみの場合は、以下の説明は飛ばしてCloudflareのアカウントAのWAF設定 に進んでも大丈夫です、と思います。
【事例紹介】2つのCloudflareアカウント、9サイトのWAF設定方針
Cloudflareの無料アカウント2つに2ドメイン9サイトぶんが入っています。■CloudflareのアカウントA
同じ1つのドメインでドメイン1つ・サブドメイン1つあり、どちらもWordPressです。
- サイトその1(WordPress。AI・検索エンジンともに、WordPress管理画面以外はインデックス許可■・クロール許可■)
- サイトその2(WordPress。AI・検索エンジンともに、WordPress管理画面以外はインデックス許可■・クロール許可■)
以下、難易度がグッと上がります><
■CloudflareのアカウントB
同じ1つのドメイン(アカウントAとは違うドメイン)でドメイン1つ・サブディレクトリ1つ・サブドメイン5つあります。
- サイトその3(WordPress。会員用サイトなので、AI:クロール拒否・インデックス拒否/検索エンジン:クロールはしても良いけどインデックス拒否)
- サイトその4(WordPress。会員用サイトなので、AI:クロール拒否・インデックス拒否/検索エンジン:クロールはしても良いけどインデックス拒否)
- サイトその5(WordPress。AI・検索エンジンともに、WordPress管理画面以外はインデックス許可■・クロール許可■)
- サイトその6(WordPress。会員用サイトなので、AI:クロール拒否・インデックス拒否/検索エンジン:クロールはしても良いけどインデックス拒否)
- サイトその7(WordPress。会員用サイトなので、AI:クロール拒否・インデックス拒否/検索エンジン:クロールはしても良いけどインデックス拒否)
- その8(Laravelサイト。フロントページなのでAIにも検索エンジンにもインデックス許可■・クロール許可■)
- サイトその9(Laravelサイト。管理画面なのでAI・検索エンジンともに拒否)
CloudflareのWAF設定でAIボットに関して、■だけ許可、それ以外は拒否します。
CloudflareのアカウントBがちょっとややこしいので、WAF設定に注意・工夫が必要です。
ここまでの諸々の作業にて、サイトその1258以外の5サイトに関しては必要に応じて、
■.htaccess
#■■■X-Robots-Tagを追加■■■
<IfModule mod_headers.c>
Header always set X-Robots-Tag "noindex,nofollow,noarchive,noimageindex,noai"
</IfModule>■robots.txt
- 各AIボットを拒否
- 各検索エンジンのボットAIボットは許可
■header.php
<!--■ボットとAIのクロールを拒否する■-->
<meta name="robots" content="noindex, nofollow, noarchive, noimageindex, noai">
<meta name="bingbot" content="noindex, nofollow, noarchive">
<meta name="pinterest" content="noindex, nopin">となっています。
その上でさらにCloudflareのWAF設定を追加する理由は、(Bytespiderのように)robots.txtやheader.phpのnoindexの記述を無視するAIボットがいくつかあるので、AIボットをより確実に拒否するためです。
あらためてこの9サイトに関して、AIボットおよび検索エンジンのクロールを拒否するWAF設定の方針をまとめると、
■CloudflareのアカウントAの2サイト
- サイト12(WordPressサイト)は、WordPress管理画面はAIボット・検索エンジンを拒否/それ以外はAIボット・検索エンジンを許可■
■CloudflareのアカウントBの7サイト
- サイト8(Laravelサイト・フロントページ)は、全てのURLでAIボット・検索エンジンを許可■
- サイト5(WordPressサイト)は、WordPress管理画面はAIボット・検索エンジンを拒否/それ以外はAIボット・検索エンジンを許可■
- サイト3467(WordPressサイト)およびサイト9(Laravelサイト・管理画面)は、全てのURLでAIボット・検索エンジンを拒否
■だけ許可、それ以外は拒否します。
CloudflareのアカウントAだけならCloudflareの設定 → セキュリティ → ボットの「AIボットをブロック」の一括設定で
- AIボットをブロック:有効
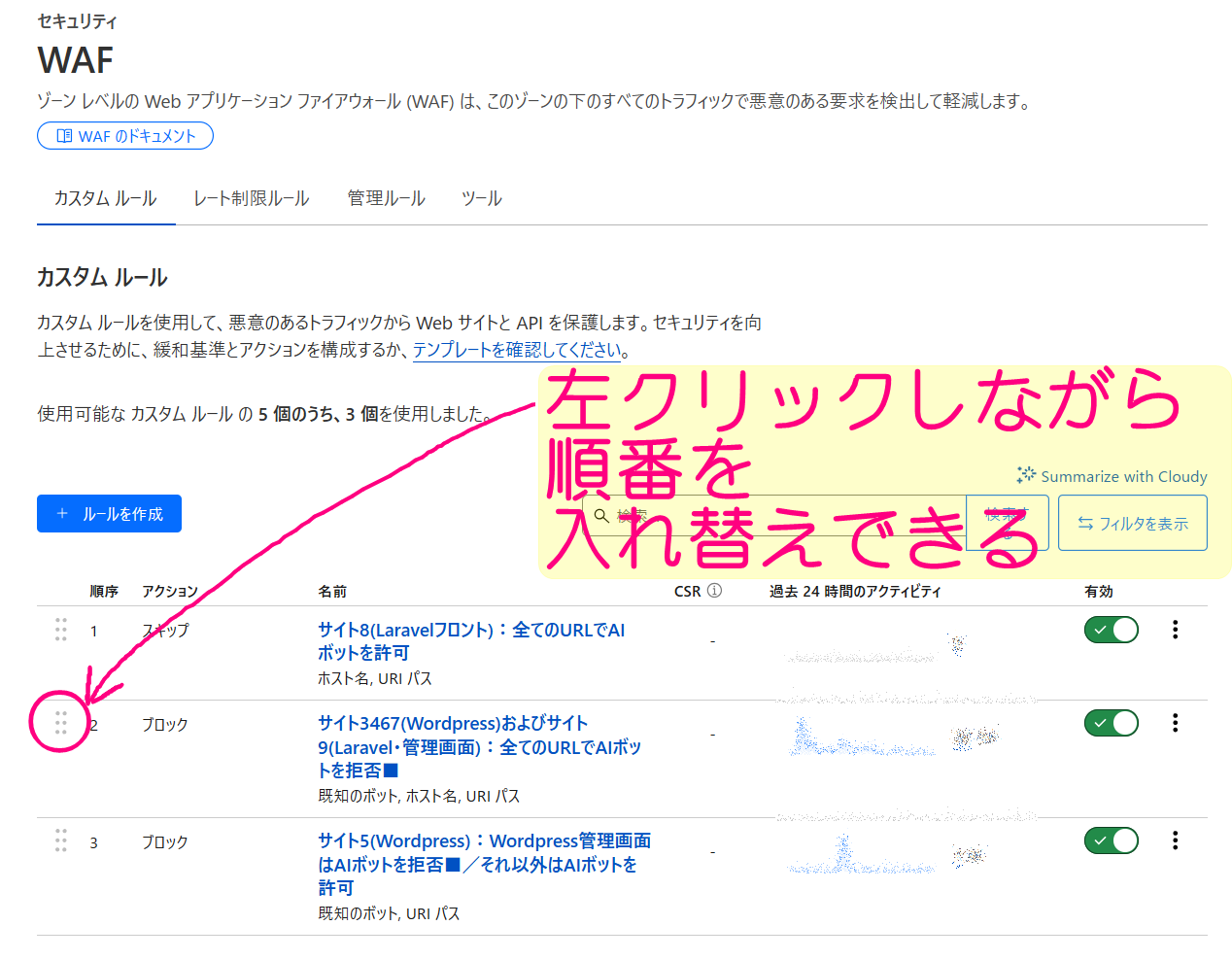
でもOKですが、それだとサイト8が検索結果に表示されなくなるのでCloudflareの設定 → セキュリティ → WAFのカスタムルール(※2)で対応します。
※2 新しいダッシュボードの場合は、Cloudflareの設定 → セキュリティ → セキュリティルールにて、「+ルールを作成」のカスタムルール
CloudflareのアカウントAのWAF設定
- WordPressで1サイトのみの場合は、以下の通りでOKです。
- WordPressではない1サイトの場合は、値:/wp-admin/ の箇所を管理画面のURLの一部に修正すればOKなはずです。
それ以外の場合は CloudflareのWAFでAIボットを拒否する を全てしっかり読んでから慎重に設定して下さい。
Cloudflareの設定 → セキュリティ → WAFのカスタムルール(※3)にて、
■ルール名:サイト12(WordPress):WordPress管理画面はAIボットを拒否■/それ以外はAIボットを許可
フィールド:既知のボット
オペレーター:次と等しい(グレーアウト)
値:チェックON
and
フィールド:URIパス
オペレーター:次を含む
値:/wp-admin/
「式を編集」だと (cf.client.bot and http.request.uri.path contains "/wp-admin/")
アクション:ブロック
※3 新しいダッシュボードの場合は、Cloudflareの設定 → セキュリティ → セキュリティルールにて、「+ルールを作成」のカスタムルール
「検証済みのボット」と「既知のボット」の違い
フィールド:既知のボット
オペレーター:次と等しい(グレーアウト)
値:チェックON
ではなく
フィールド:検証済みボットのカテゴリー
オペレーター:次と等しい
値:AIクローラー
でブロックするという方法もあるみたいですが、Cloudflareの検証済みボット

を確認してみると、AI Crawlerに該当するBOTは
- GPTBot
- GoogleOther
- Meta-ExternalAgent
- PetalBot
- Factset_spyderbot
しかありません。
CloudflareのWAFにて、
■検証済みボット
Googlebot、Bingbot、Slackbotなど、Cloudflareが信頼性を検証した既知の良性ボットを指します。
Cloudflareが検証して信頼性の高いボットと判断したやつなので、後述のBytespiderみたいにお行儀の悪いボット(できるだけ拒否すべきボット)ではなく、代表的なAIボットの立ち位置です。
■既知のボット
Cloudflareが識別して検証した、ボットの広範なリストです。
良性ボットだけでなく、悪意のあるボットや疑わしいボットも含まれます。
| 項目 | 検証済みボット (Verified Bots) | 既知のボット (Known Bots) |
|---|---|---|
| 対象 | 信頼できるボットのみ | すべての既知ボット (良いボット + 悪いボット) |
| Googlebot・Bingbot など | 許可 | 含まれる (ただし、拒否すると検索エンジンのクロールを止める可能性がある) |
| 悪意のあるボット (Bytespider など) | 含まれない | 含まれる |
| SNS クローラー (Facebook, Twitter, Slack) | 許可 | 含まれる |
| スクレイピングボット | 含まれない | 含まれる |
| セキュリティリスク | 低い (安全なボットのみ) | 高い (悪意あるボットも含む) |
ということなので、「検証済みボット」よりも「既知のボット」でブロックしたほうが良い気がします。